使用各種分類模型的時機
概要: 前面7天學了各種分類模型以及使用方法. 但學了這麼多,還是要了解一下各個模型的強弱之處,以便於未來能夠因應各種不同的情況來選擇最適合的模型.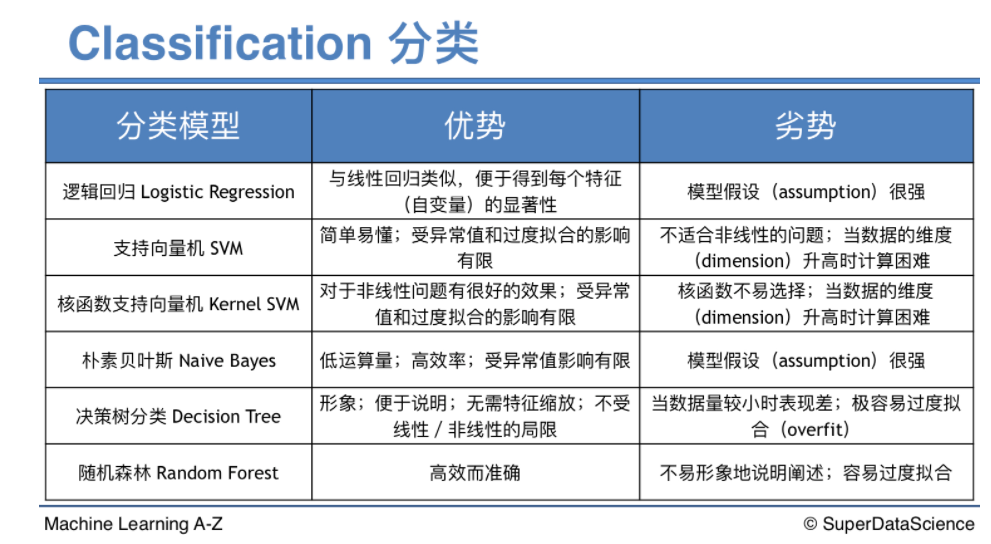
{如何根據各個模型的強弱來決定使用何者}
1.希望預測最終概率的情形:
線性問題: 邏輯回歸
非線性問題: 樸素貝葉斯
2.希望預測所屬集群或分布:
SVM
3.希望非常直觀的闡述所示模型:
Decision tree
4.最準確的模型,且不太在意模型的闡述方式:
Random forest
{偽陰性, 偽陽性}
偽陰性: 把正向的結果表示為負
偽陽性: 把負面的結果表示為正
結: 偽陽性的嚴重性比偽陰性來得更嚴重,若是不懂就想想醫生的例子: 本來有病, 結果醫生告訴你沒病,會拖延到治療,導致結果更為嚴重
{CAP CURVE 累積準確曲線}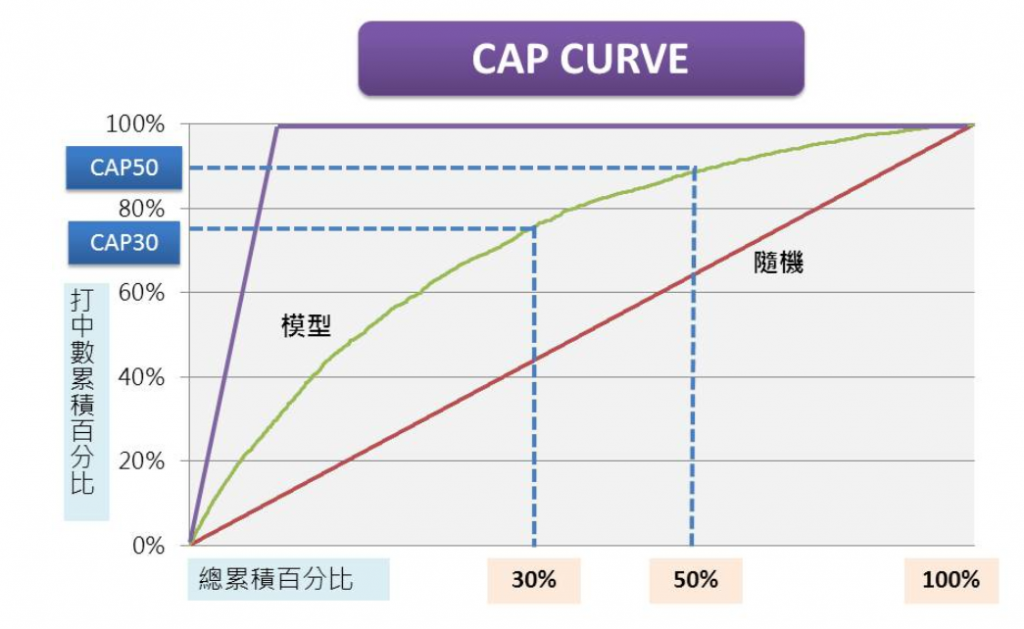
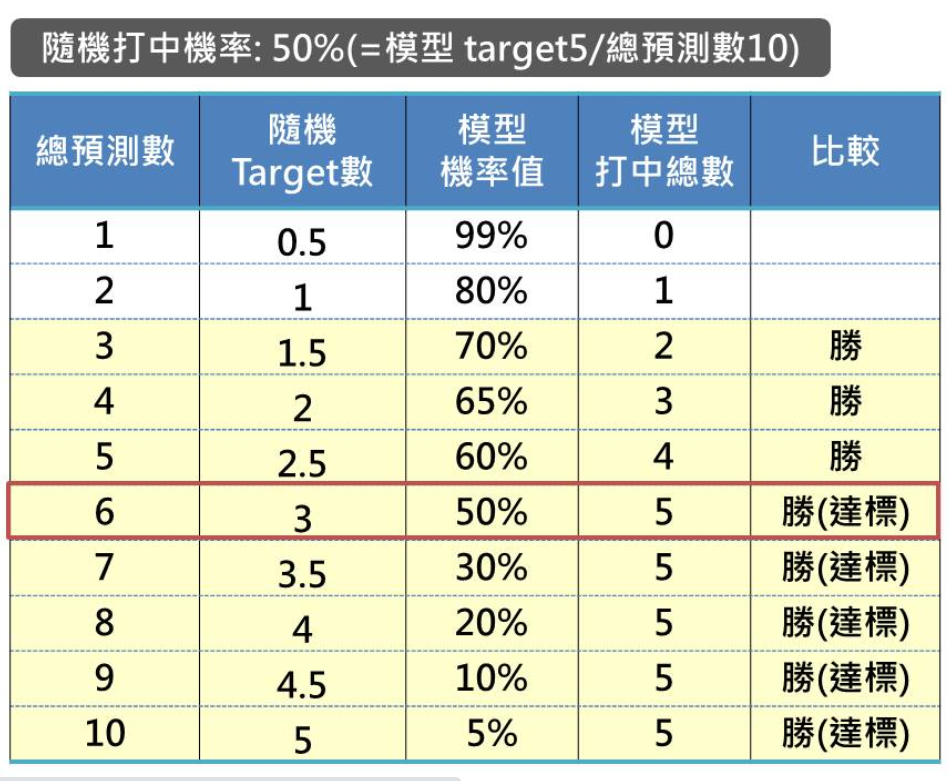
假設我們要預測10個人中誰是有可能成績不及格被當,已知10位母體中有5個人被當,那麼我不用用模型,隨便用猜的就應該有50%的命中率,畢竟母體裡就有一半的人是被當的人啊!
這就代表用模型的準確率必須高於50%,模型才具有說服力。我將這10個人依據被當機率值從大到小排序,成績最差的排最前面,然後設定機率值50%以上就算命中。
從下表中可以看到,第一筆預測99%被當機率的人其實沒被當,所以模型打中數是0,代表這筆被蠻嚴重的錯估了。但是第2筆到第5筆,模型預估的不及格機率值都蠻高的,這些人也都確實有被當,因此這個模型在第6筆就準確抓完5個被當的學生,遠高於第六筆的隨機值3個,模型準確率如同射氣球高手一樣,非常高!